Buggy blog
Blog
Debugging is dead, long live Vibe Debugging
By Anicet, maintainer of Ariana.dev
on 11/04/2025
on 11/04/2025

Almost no one uses a debugger, yet everyone, including me, goes deep into the mines, debugging with their printf pickaxe and console.log lantern, everyday, getting frustrated over it and losing everyone's precious time, which would be better spent:
1
taking care of our loved ones
2
learning how to best be enslaved by a combo of Claude and the 36 gazillion new MCP servers which appeared since yesterday
Thinking about it, it made me reach the following conclusions:
—
Current debuggers are not user friendly enough to prevent us from using a quick lazy print instead, except in rare cases where its the de-facto tool for the job
—
They are not cool enough to grow in popularity from evangelization alone
—
This will not change until the concept of debugger itself is reinvented and becomes fun to use
So here is my proposition for a New Fun Debugger. It shall be:
1
So easy and low maintenance that you cannot be lazy and decide not to use it
2
Helpful to debug across the stack, like tracking data flow across backend, frontend, services, robots, kitchen appliances, ballistic missiles, whatever...
3
Helpful to decorticate and visualize complex structures, such as tensors, trees, global states, and watch them evolving over time
4
Helpful to understand fucked-up async, parallel, reactive code execution patterns
5
Despite all of the above, a lot of people will not change their muscle memory for anything if it's not Cursor tab. So it should be powerful & cost-saving enough for AI coding agents to fix your vibe coded mess with, saving them from eternal guess work and putting logging everywhere but not where it'd actually be useful
That's why my co-founder and I are building Ariana.dev: Some sort of new-age "time-travel" debugger for Python, JS & TS that strives to do all the above. This article is an in-depth post about, first, "What is Ariana", after that, "Why classic debuggers and AI for debugging are so limited", then, "How we designed it", and finally, "How we built it".
Ariana is made in Rust btw 😎.
What is Ariana, what does it do?
tl;dr: Run ariana alongside your code to:
—
Be able to hover any line in your IDE and figure out:
1
was that line/block executed or skipped when the code ran
2
what was the value of the variables & expressions at that point
—
Be able to feed to an LLM all the above information to fix your bug
—
All of the above without needing to insert logging or breakpoints in any way
Basically it's what vibe coding is to coding, for debugging, minus the part where it doesn't really work. It's vibe debugging.
You can watch an unashamed 🚀🦄✨ startup-style demo of Ariana just below (or just move on with a text equivalent just below if you're more into reading):
User-facing, Ariana is both an IDE extension and a command in your terminal. You first have to run your code from the terminal with the ariana command as a prefix. For example that could be ariana npm run dev if you live in a JS/TS project, or ariana python main.py if you live on Jupiter in a regular Python project (we don't support notebooks yet sadly). You can do that to run any number of parallel modules in your project, let's say most probably a frontend and a backend in the web world, or a simulation and a training script in the ML/RL world.
Now, live, as your code runs, you can see execution traces being captured in the extension and explore them in the UI to understand which lines got executed in your code, in what order. You can also notice parts of your code that the extension has highlighted. This means your code went there. If its highlighted in green it ran correctly, if it's in red it threw an error. Then you can hover these highlighted sections to reveal what values they got evaluated to.
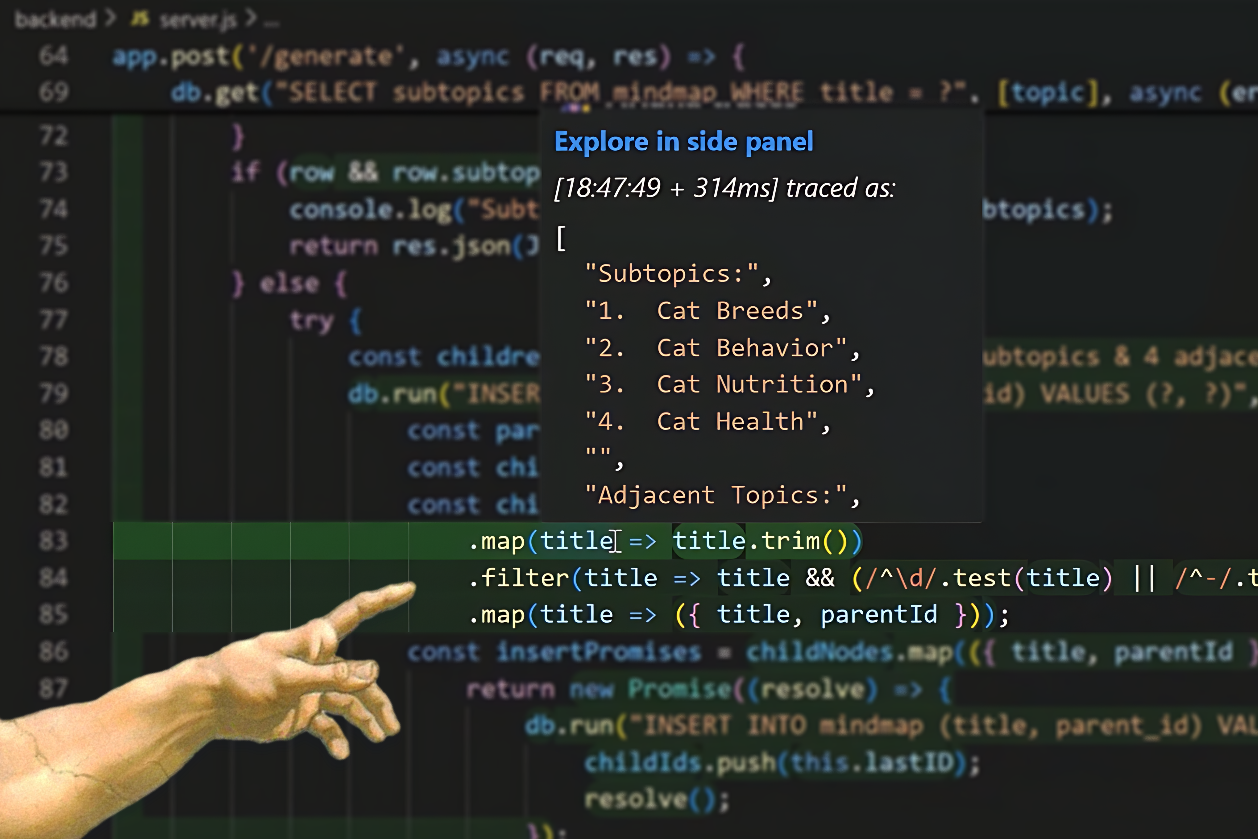
This saves you a ton of time debugging because now you can simply:
1
always run your code with Ariana in development (and in production if you don't mind the performance overhead)
2
if an error or something weird occurs, don't bother reproducing and cluttering your codebase with print statements:
—
just explore the traces or look for green/red highlighted sections in your code
—
quickly check the past values of variables and understand your bug's root cause at a glance
3
fix the bug yourself or pass the traces as context to your best AI friend to do the dirty guess work
4
voila, probably saved 15 minutes (best case) or sometimes a few days (worst case)
Why we do what we do
Just me or no one uses a debugger?
I started coding as a teenager in 2015, tinkered with many high-level languages like TI-BASIC, JS, Python, you know, the good old days... As I did, I slowly got hooked by typed languages: Java, TS, C#, low-level programming: C, C++, Assembly (less than the lethal quantity), and even did a detour to crazy land with Elixir, Go, Rust and GLSL (that's the moment I started seeing things).
I'm yet to try Zig, Odin, Gleam, although I have to confess I read their specs and I'll be inexorably drawn to their light one day like the blazingly-fast well-hydrated Server-Side-Rendered JS framework mosquito I am.
During that journey, I explored, built and maintained a bit of everything: game engines, online games, web backends, frontends, databases, discord bots, deep learning frameworks, compilers, parametric CAD libraries, heck even models to detect aliens black holes around binary stars, amongst other things... So you might say with this background, I'm an expert at nothing... if it's not trying to use Javascript to solve all the problems in the visible Universe, so I can then spend my weekends rewriting it all in Rust.
Yep that's me.
One important thing I noticed during what are now the first 10 years of my journey, is that almost never, except at point gun during my time in college, while certainly fixing some C++ null pointer foot-canon atrocities, did I think: "Hey that would be a good idea to use a debugger right now, let's do it!".
Like actually never. And instead I've used logging. Basic, stupid, console.log and print. But you know, I'm not slow actually, I can debug and ship pretty fast (to my previous employers' standards at least).
And it's not just me, with rare exceptions, none of my fellow students when I was still in college, colleagues when I got to work for large successful businesses, none of the researchers, startup folks, heck even hardcore programmers I've met use a debugger everyday. But everyone debugs and troubleshoots code everyday with logging, everyone spends hours doing so. "We go deep in the mines everyday", as the maintainer of BabylonJS once told me (he might be using a debugger way more often than most of us do though, can't beat game engine magicians at this).
So why does no one use a debugger?
But it's not just that we suck at using debuggers, or are too lazy. It is that we have to debug the most absurd, microserviced, parallel, spaghetti software, with f*cking print and console.log, because debuggers aren't even the beginning of the commencement of the solution when it comes to solving such bugs!
Then we push 300 LoC long Factory-Mold-Injected logger configurations to prod and pay crazy bucks to SaaS companies to show it all in a nice dashboard that feels terribly daunting at first, and terribly alienating at last. Oh and now your code is full of decorators and logging that riddles your business logic btw. All of which is often useless because bugs, for some reason, always appear at the place you think the least of.
So why no better tooling exists that tries to make troubleshooting development and production code more satisfying?
As you will understand, building Ariana, and probably any other system that tries to answer similar requirements, although a first version was shipped quite fast, requires, at scale, a significant engineering effort both wide and deep.
My co-founder and I love pain it seems, so we are fully ready to embrace it, give it a soul, find funding, talent and time for it. But it seems reasonable to me that too few people (but by no means no one!) have been crazy enough in the past to attempt it for long enough. Another possible reason is that without AI, the useability, feasibility, or simply scope of such tools is necessarily underwhelming.
How we design it
Our approach is mainly drawn from first principles, our observations and interviews with users, and our guts. Rather less by what other projects exist in the space of time travel debugging + AI.
It has to look inside
I have a strong belief that the more costly a bug is, the least likely it is to be identified & fixed early by either:
1
a static analysis tool such as a linter or compiler
2
Claude, ChatGPT & co
3
the person who reviews your PR
4
the existing test suite
That is because all these tools (sorry dear PR reviewers) will mostly just read the code, at best simulate it with example inputs. I know, sometimes you can formally prove programs but it is out of scope here. Basically, none of these can really predict the space of possible input/software/output interactions going on in real life because the scope of the whole thing, especially in production, easily scales exponential or factorial with the number of lines you add to the codebase. (unless your code is fully made of perfect non-leaky abstractions, in which case I give you a nice "Champion of useless Slop" medal, yes you, take it, I'm proud of you :D).
So requirement 1), if it gotta hunt bugs, it must know something about the internal state of the code when it is running (I know shocking, right).
It has to look at everything
But knowing the internal state is not just helpful to identify the bugs.
If you know enough about that state, by that I mean: at least all the parts of the internal state that impact your business logic in some way, then you can simply skip ever having to reproduce your bugs. You can just look back in time, monitor every interaction till the root cause. And if you want to test changes, you can just load a checkpoint of the state and go from there.
And that is the real win in my opinion: the real bottleneck in debugging, whether it is with debuggers or print statements, is to actually reproduce the bug, as many time as needed to fully understand the sequence of actions. Normally you have a trade-off, between how much instrumentation (breakpoints, logging...) you're willing to handle or care about, and how likely you are to figure out the bug during the first re-run. Imagine instead if you could just watch the entire state, no compromise. Then you would not even be reproducing once. You would go straight to the traces that were produced when the bug originally happened. With breakpoints or logging unfortunately that would be super cumbersome to do.
So requirement 2) is that at minimum, the entirety of the business-logic-impacting internal state of the code when it is running must be captured.
It has to sync the un-syncable
Complicated, buggy software, and increasingly so in the future if we believe AI empowers individual contributors to take on larger and larger projects over time, is set to be:
1
Distributed in many independent modules
2
All of which possibly run in parallel on different machines
3
All of which possibly communicate with one another
4
All of which possibly are designed, implemented, maintained:
—
by different people or AIs
—
using different tech and languages
Btw, if you think about it, it already is the case: Even the most boring, basic web slop out there is already backend + frontend, running on 2 different machines (and technically with SSR+hydration your frontend runs on both server and client), sometimes both components are even made by different teams, and often with different programming languages (Unless you want to also use some JS in your backend, no judgement I did that too before AI became able to handle Rust lifetimes and write Actix middlewares for me).
Now think of the future of AI and robotics: A RL training/inference setup is crazy distributed across machines, tech, languages. First you have the whole holy tech stack of the simulation of the robot/game/whatever in C++/C#, which is its own hell, and then you have communication with a web server in Go or TS, which behind the hood is a massive training cluster with modules in Python, JAX, Fortran, CUDA. And all of that is entangled and mixed together in quite intricate ways.
Which raises:
1
How the fuck you debug that with GDB
2
How the fuck you debug that with console.log
3
How the fuck you debug that at all!!!!!
Unless you have polluted your entire code with open-telemetry style logging (good luck maintaining that) and paid sentry big bucks to aggregate all' that, I don't have a clue how you debug in these environments (skill issue maybe? let me know how you do if you have first-hand experience).
So requirement 3), 4), 5) and 6) are:
3
It should be multi-lingual
4
It should track not only codebase-internal interactions but inter-codebase interactions
5
It should be low-maintenance (not having you to put too many new lines in your code, if any)
6
It should offer robust summarization, visualizations and search to handle the size and complexity of the generated data
And still be simple?
It should empower small players to play in the field of the big players, and allow the big players, given they are willing to adopt the change, to deliver even more behemoth projects at an even lower cost.
A good tool should be easy to start with, albeit maybe hard to master. Like all good tools out there: Python, the web, print statements. Too many time-travel debuggers are targeted at their creators instead, who are awesome but non-average programmers, the kind who are hardcore on Rust and C++, and still occasionally write Assembly for fun. I see too many dev tools that require you to know too much, setup too much: CI/CD, large configs, self-hosting with Docker. Come on, we can do better.
So final requirement 7) is that is should be as easy to use, if not easier, than putting even a single print statement in your code.
Non-goals
Some might be rolling their eyes at the scope. And indeed, building such a tech entails massive challenges, hence we added some constraints:
1
It will not work with all languages
—
The tech will require specialized tooling for each language, mostly because static analysis is required to identify where it is relevant and non-breaking to instrument your code. So support for your favorite niche language, or for languages that are significantly harder not to break, like C++, will come when we can afford to.
2
It will not be local-first
—
Rewriting 10k+ files codebases with instrumentation, syncing multiple parts of your stack, handling millions of traces per run, asking LLMs to crawl all of that to find root causes of bugs: all of this would have a worse user experience if it runs, bugs, and has to be updated all at once on your specific machine/OS. For now we believe that at best we can offer some day a self-hosted version of the code instrumentation heuristics and the trace collection & analysis system (both are super finicky, updated frequently and too secret-saucey).
3
It probably won't be 0 overhead. Think like the overhead of going from C to Python at worst, and the overhead of having a print statement every 2 lines at best.
—
Compute becomes cheaper every year. I know, whether the Moore Law still is a thing is debatable, but we can't say most of the code that bugs out there, in a way a debugger like Ariana would really help to solve, is really that compute intensive, it's mostly all IO-bound.
—
You won't use it on your battle-tested core libraries/engines/kernels
—
You will probably use it in development first and already unlock a significant chunk of the value it has to offer depending on your use case
—
Over time we will still optimize it and scrap every bit of performance we can. In the last 20 days we've already made Ariana ~73x less overhead (by switching from writing logs to file to stdout logging. Yes, same as you, I wonder what we were thinking.). I still see room for at least 10x to 20x less overhead.
So how do you build that crazy thing?
I won't go too much into the details because secret sauce. But from a high-level point of view we have identified 2 strategies to implement a tool like Ariana:
1
Programmatically rewrite the code with fancy instrumentation
—
Pros:
—
Sky is the limit with the granularity of your instrumentation
—
Sky is the limit with how you collect, filter and organize execution traces during run time
—
Every language can easily print or send network requests, almost
—
Can track even parallel/async executions if you add random IDs everywhere.
—
Overhead? Given printing is fast and I can decide exactly what bit of memory to poke or not, idk if it gets better than that. (no comparative benchmarks to back that up)
—
Cons:
—
Must rewrite code which is super error prone (its a transpiler of sorts)
—
Must implement that for every individual language
—
Some languages you cannot inspect everything you want without breakpoints (Rust, C, C++...) but I have ideas still
—
Now, official stack traces might look like shit because your code now looks like shit, but with a code-patterns map that will be fixed eventually
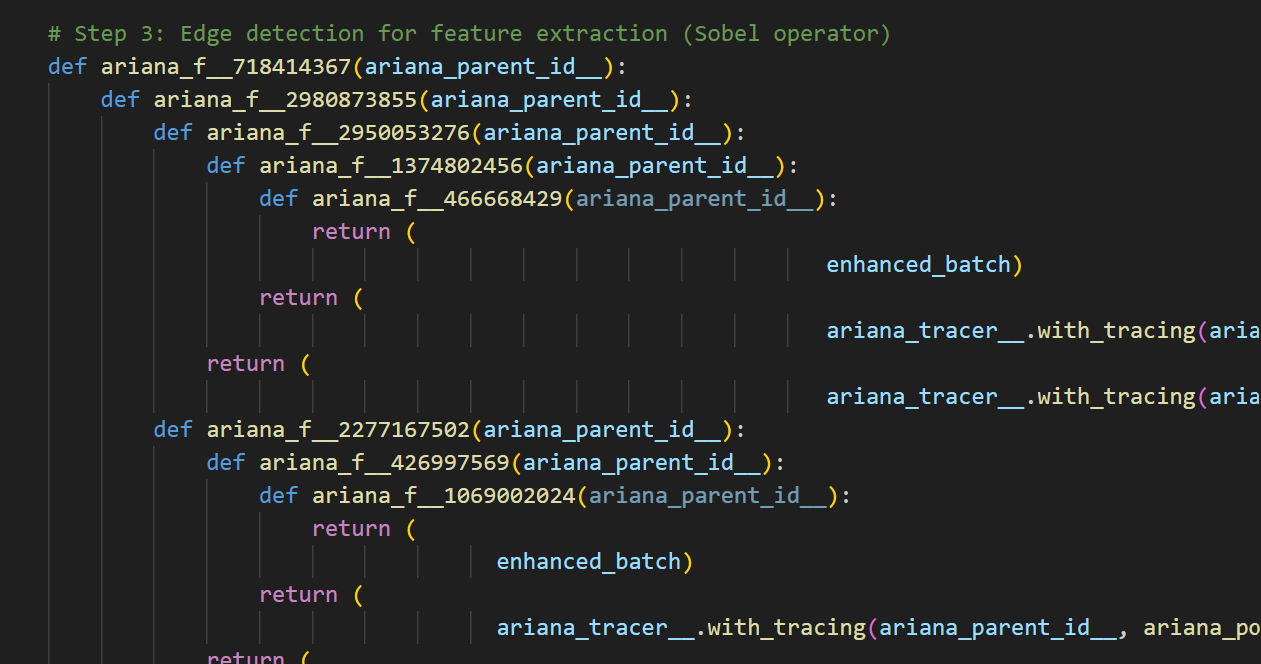
Some Python code, beautifully spaghettified by Ariana.
2
Or programmatically use a debugger to put breakpoints everywhere
—
Pros:
—
Feasible quickly in every language, could even unify them under higher-level debugging APIs like VSCode's
—
Super easy to instrument the code (just put breakpoints almost everywhere)
—
Low overhead? Maybe, idk to be fair, is shuffling through every single debugger stop really that efficient assuming it dumps the entire stack? I don't know the internals enough to guess.
—
Cons:
—
How do you debug and keep track of logic flow in parallel code? PIDs? How do you not end up rewriting the code anyway?
—
How do you debug and keep track of logic flow in async code? (no fucking idea, modify each runtime? yikes)
—
How do you break-down expressions in single lines? (can be done but not so for free)
—
Users must have a third-party debugger installed (and for some languages, our fork of their runtime lol)
Obviously went for strategy 1) and it is going fine so far. Maybe an hybrid approach is the future. As a consequence of using this strategy over the other, I'd say that Ariana is pretty easy to install, easy to use, and low-maintenance for the end user. It is more of a nightmare to implement and maintain for us, but hey, we're here to do the dirty work.
Then on the backend, you just make the best execution traces database & search engine & debugging AI agent possible. Of course that scales poorly, that's why it is all in blazingly fast Rust, get it now? (no, I don't have benchmarks, what for?) Also tree-sitter is cool (and sometimes hangs so I have to run a separate Rust binary that I can kill as needed...).
One very tricky part though is syncing traces across concurrent code modules from different codebases and in different languages (for example: how do you establish that function call F1 in codebase A is what triggered via http that function call F2 we can't figure out where it comes from in codebase B). For now we do it all based on timing as we don't feel confident messing with our users' communication protocols. But pretty sure with a mix of reading the surrounding code, surrounding traces and timings we'll reach a good-enough accuracy. That also scales poorly and is a lot of fun algorithmic work to try improving.
Finally, slap that to your own fork of VSCode existing IDEs with HTTP and Websockets (dont' get me started on how the highlighting UI works in VSCode that's its own nightmare...), and to State Of The Art AI Coding Agents (SOTAACA) with MCP or whatever other acronym is trendy right now.
Do you guys plan to make money?
Yes, and we have raised some capital. We are two 20-something year old humans with barely any savings who need to eat and stay alive long enough for Ariana to be made awesome for you, and robust enough to appeal to enterprise clients that can make the project sustainable and well maintained in the long run. We have thought of other models, but this is the one we chose in the end.
Yes, we want it to be as open and free as we possibly can. For now we think that every debugging feature that isn't AI should be free and possibly self-hostable in the near future. Our frontend (IDE extensions and CLI) should be source-available at minimum (open-source on github under AGPL for now) for transparency's sake, but no, we don't feel confident giving away the sources of the backend yet. We often think about saying "fuck it" and fully open-sourcing it all. We at least strive to regularly (re)assess the massive pros and massive cons attached with it.
Conclusion
Hope this whole thing convinced you:
—
that Ariana is v cool
If you use serverless, I'm glad to let you know that your code is IO-bound enough for Ariana not to make it too slow in prod
—
to not try to reproduce Ariana at home (because you can join us so we join forces instead :D)
—
to try Ariana at home (and let us know if it breaks because it very well might, but we have no other ways to improve it)
Ariana was built during the last 2.5 months, initially shipped 1.5 month ago. The road to building Ariana is still super super long ahead of us, with many technical and product hurdles we will have to deal with, but we're excited to embrace the challenge and grow with your feedback!
Thanks for reading till there! Have a good one everyone :)
nb: For those who ask, it is indeed called Ariana because of mythology, not pop music. We're French snobs:

Isaline (left) & I (right) probably stressing out before demoing Ariana to the public